有效利用 robots.txt
「robots.txt」檔案可告知搜尋引擎是否可以存取您網站的某些部分,進而對這些部分進行檢索。此檔案必須要命名為「robots.txt」,並放置在您網站的根目錄中

robots.txt 檔案的位址
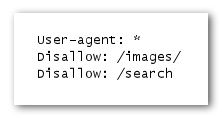
所有符合條件的搜尋引擎漫遊器 (標有萬用字元符號 *) 都不會存取和檢索 /images/ 下的內容, 或者任何以 /search 作為路徑開頭的網址
「Google 網站管理員工具」中有一個很好用的 robots.txt 產生器,可協助您建立此檔案。請注意,如果您的網站使用了子網域,且您不希望搜尋引擎 檢索特定子網域中的某些網頁,則您必須為該子網域建立一個單獨的 robots.txt 檔案
robots.txt 實作典範
• 對敏感的內容使用更為安全的方法 — 您或許對使用 robots.txt 來封鎖敏感或保密的材料感覺不是特別放心。其中一個原因是,如果網際網路上碰巧存在連至您封鎖的網址的連結 (如參照記錄),則搜尋引擎仍然可以參照該網址 (只是顯示網址,而不顯示標題或片段內容)。此外,不遵守漫遊器排除標準的一些非符合條件的或惡意搜尋引擎可能會違背您的 robots.txt 指示。 最後,好奇的使用者可能會查看您 robots.txt 檔案中的目錄或子目錄,並猜中您不願被看到的內容的網址。對內容加密或使用 .htaccess 對內容進行密碼保護是更安全的選擇。
請避免:
• 允許檢索類似於搜尋結果的網頁 (使用者不喜歡從一個搜尋結果網頁進入另一個
搜尋結果網頁,這對他們而言沒有多大價值)
• 允許檢索大量自動產生的且內容相同或稍有不同的網頁:「難道這 100,000 個
近乎相同的網頁真的應該在搜尋引擎的索引中出現嗎?」
• 允許檢索因 proxy 服務而建立的網址
參考更多SEO技巧
以上內容出自「Google搜尋引擎最佳化初學指南」繁體中文版
robots.txt 實作典範
• 對敏感的內容使用更為安全的方法 — 您或許對使用 robots.txt 來封鎖敏感或保密的材料感覺不是特別放心。其中一個原因是,如果網際網路上碰巧存在連至您封鎖的網址的連結 (如參照記錄),則搜尋引擎仍然可以參照該網址 (只是顯示網址,而不顯示標題或片段內容)。此外,不遵守漫遊器排除標準的一些非符合條件的或惡意搜尋引擎可能會違背您的 robots.txt 指示。 最後,好奇的使用者可能會查看您 robots.txt 檔案中的目錄或子目錄,並猜中您不願被看到的內容的網址。對內容加密或使用 .htaccess 對內容進行密碼保護是更安全的選擇。
請避免:
• 允許檢索類似於搜尋結果的網頁 (使用者不喜歡從一個搜尋結果網頁進入另一個
搜尋結果網頁,這對他們而言沒有多大價值)
• 允許檢索大量自動產生的且內容相同或稍有不同的網頁:「難道這 100,000 個
近乎相同的網頁真的應該在搜尋引擎的索引中出現嗎?」
• 允許檢索因 proxy 服務而建立的網址
參考更多SEO技巧
以上內容出自「Google搜尋引擎最佳化初學指南」繁體中文版




